Fluid Numerics Journal
Port, Optimize, and Scale on AMD Instinct GPUs with HotAisle
 With unmatched performance for HPC and AI workloads, scaling on AMD MI300X hardware can transform your computational capabilities—but only if your software is optimized to take full advantage. Discover how Fluid Numerics and Hot Aisle can help you seamlessly port, optimize, and scale your applications to achieve breakthrough results.
With unmatched performance for HPC and AI workloads, scaling on AMD MI300X hardware can transform your computational capabilities—but only if your software is optimized to take full advantage. Discover how Fluid Numerics and Hot Aisle can help you seamlessly port, optimize, and scale your applications to achieve breakthrough results.
Accelerating Science with GPU Software Optimization
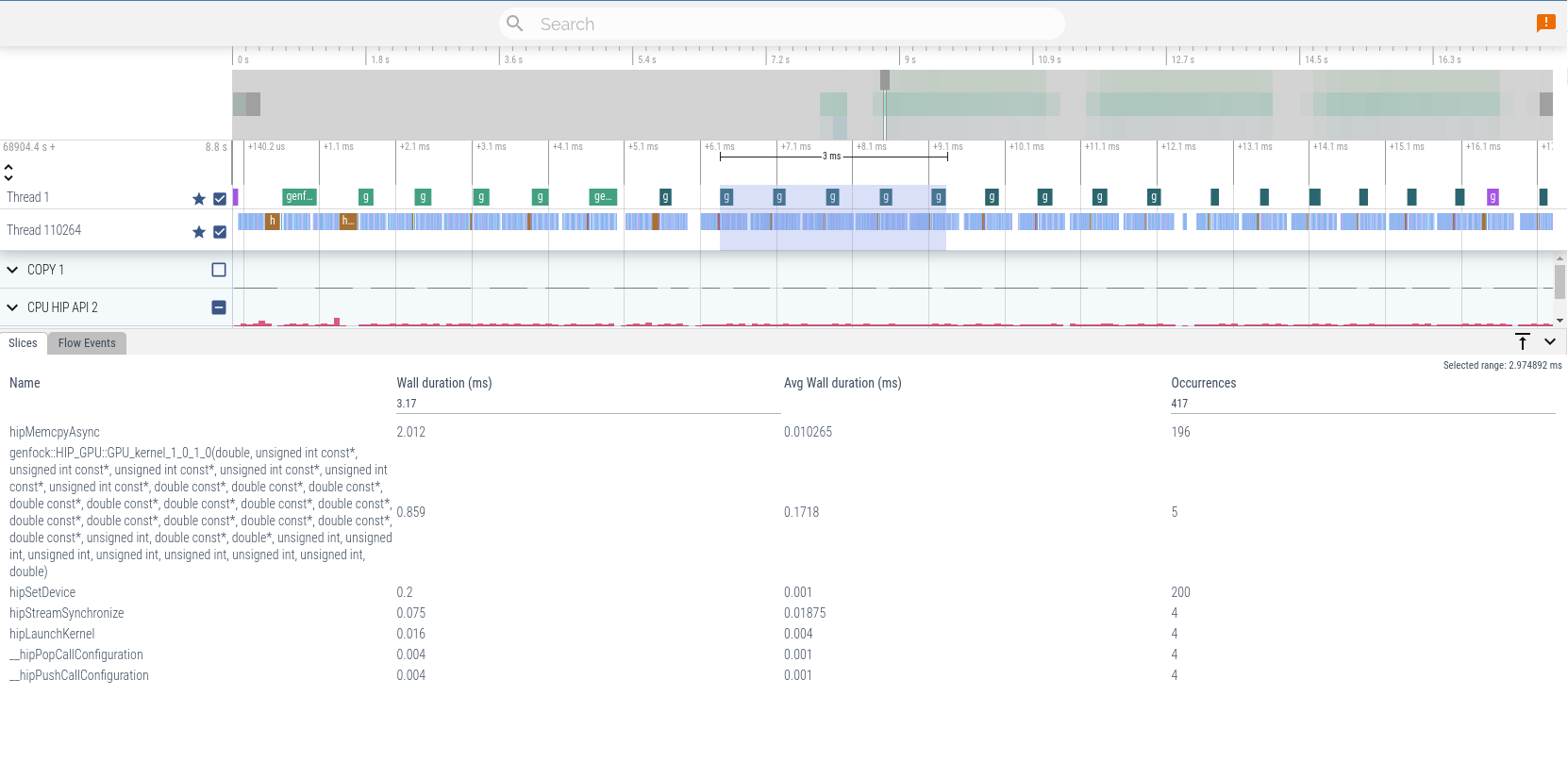 What does it take to become a finalist for the prestigious Gordon Bell Prize?
What does it take to become a finalist for the prestigious Gordon Bell Prize?
For the EXESS team, it started with a focused effort to optimize their quantum chemistry application for cutting-edge GPU hardware. Discover how our Mentored Sprint service helped them achieve breakthrough performance, unlock new possibilities, and earn recognition on the world stage. Read more
Maximizing Performance, Minimizing Costs: Energy Savings from GPU Optimization
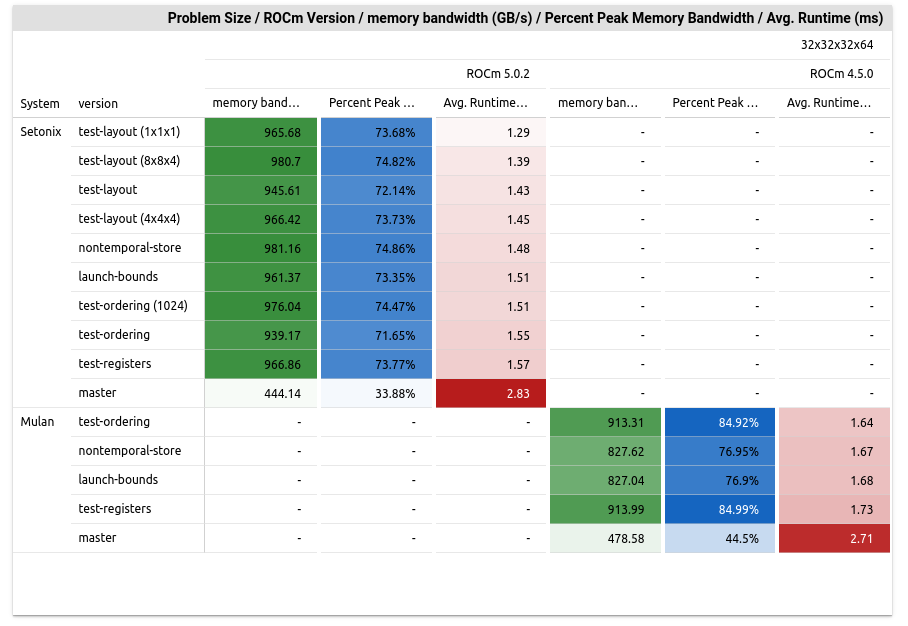 In high-performance computing, optimizing GPU workloads isn’t just about speed—it’s about unlocking hidden savings in energy and sustainability. Discover how a 1.91x performance boost turned into real cost savings and why software optimization could transform your operations. Read more
In high-performance computing, optimizing GPU workloads isn’t just about speed—it’s about unlocking hidden savings in energy and sustainability. Discover how a 1.91x performance boost turned into real cost savings and why software optimization could transform your operations. Read more
What is a mentored sprint ?
 Imagine achieving months of software optimization progress in just one week.
Imagine achieving months of software optimization progress in just one week.
Whether you're optimizing performance, porting to new hardware, or tackling costly inefficiencies, our Mentored Sprint service delivers fast, measurable results. Discover how teams are transforming their applications, cutting costs, and future-proofing their software with expert guidance. Read more
HIP Performance Comparisons : AMD and Nvidia GPUs
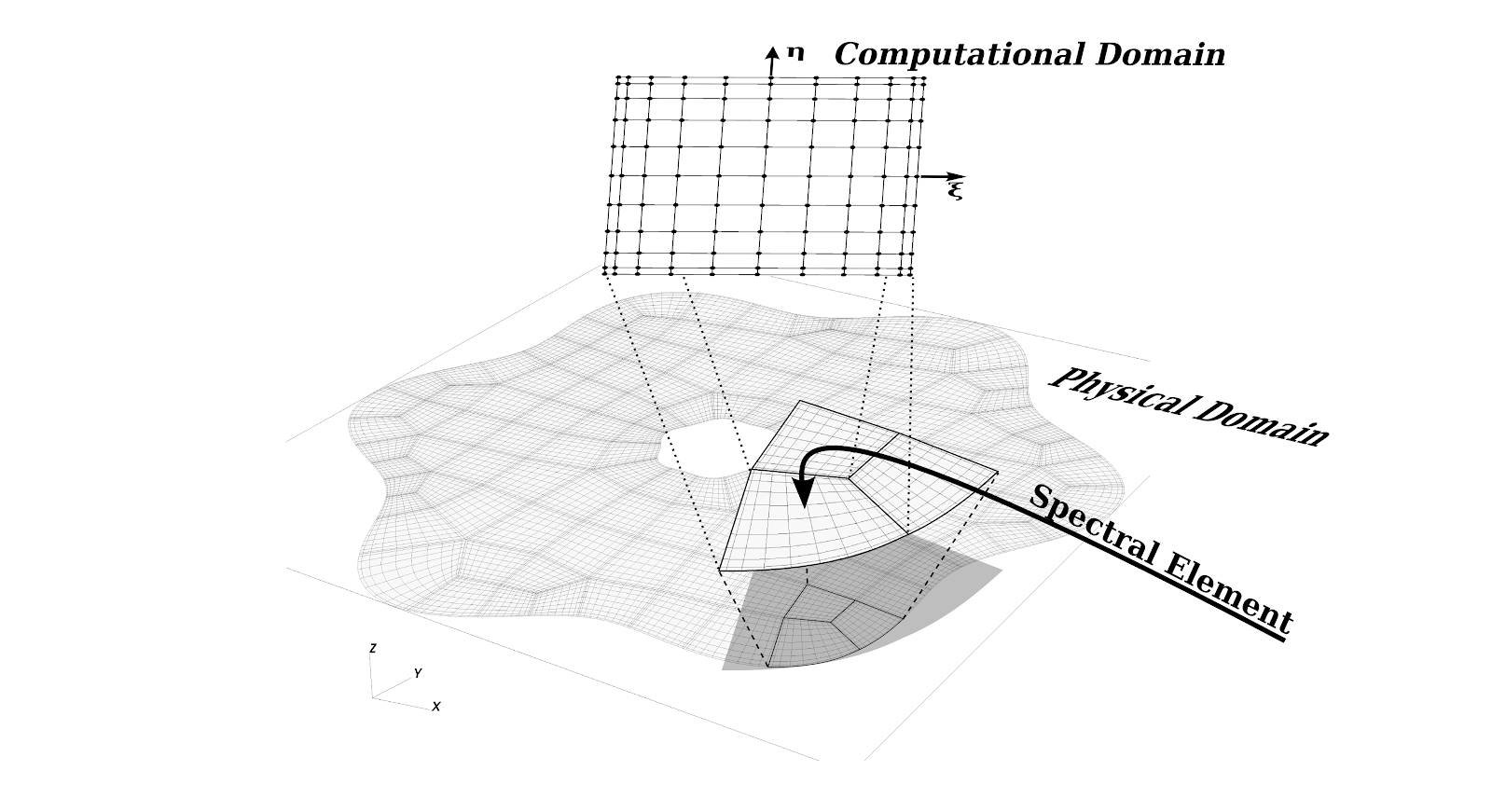 If you've read some of my other posts, you're aware I'm in the midst of refactoring and updating/upgrade SELF-Fluids. On the upgrade list, I'm planning a swap-out of the CUDA-Fortran implementation for HIP-Fortran, which will allow SELF-Fluids to run on both AMD and Nvidia GPU platforms. This journal entry details a portion of the work I've been doing to understand how some of the core routines in SELF-Fluids will perform across GPU platforms with HIP. Read more
If you've read some of my other posts, you're aware I'm in the midst of refactoring and updating/upgrade SELF-Fluids. On the upgrade list, I'm planning a swap-out of the CUDA-Fortran implementation for HIP-Fortran, which will allow SELF-Fluids to run on both AMD and Nvidia GPU platforms. This journal entry details a portion of the work I've been doing to understand how some of the core routines in SELF-Fluids will perform across GPU platforms with HIP. Read more